UNAM
UNAM elabora base de muestras que será útil para identificar voces en casos de secuestro y extorsión
Los investigadores trabajan en este proyecto con la División de Estudios de Posgrado e Investigación de la Facultad de Odontología UNAM, ya que ahí acuden pacientes que requieren o usan estos aditamentos y han decidido participar en el corpus.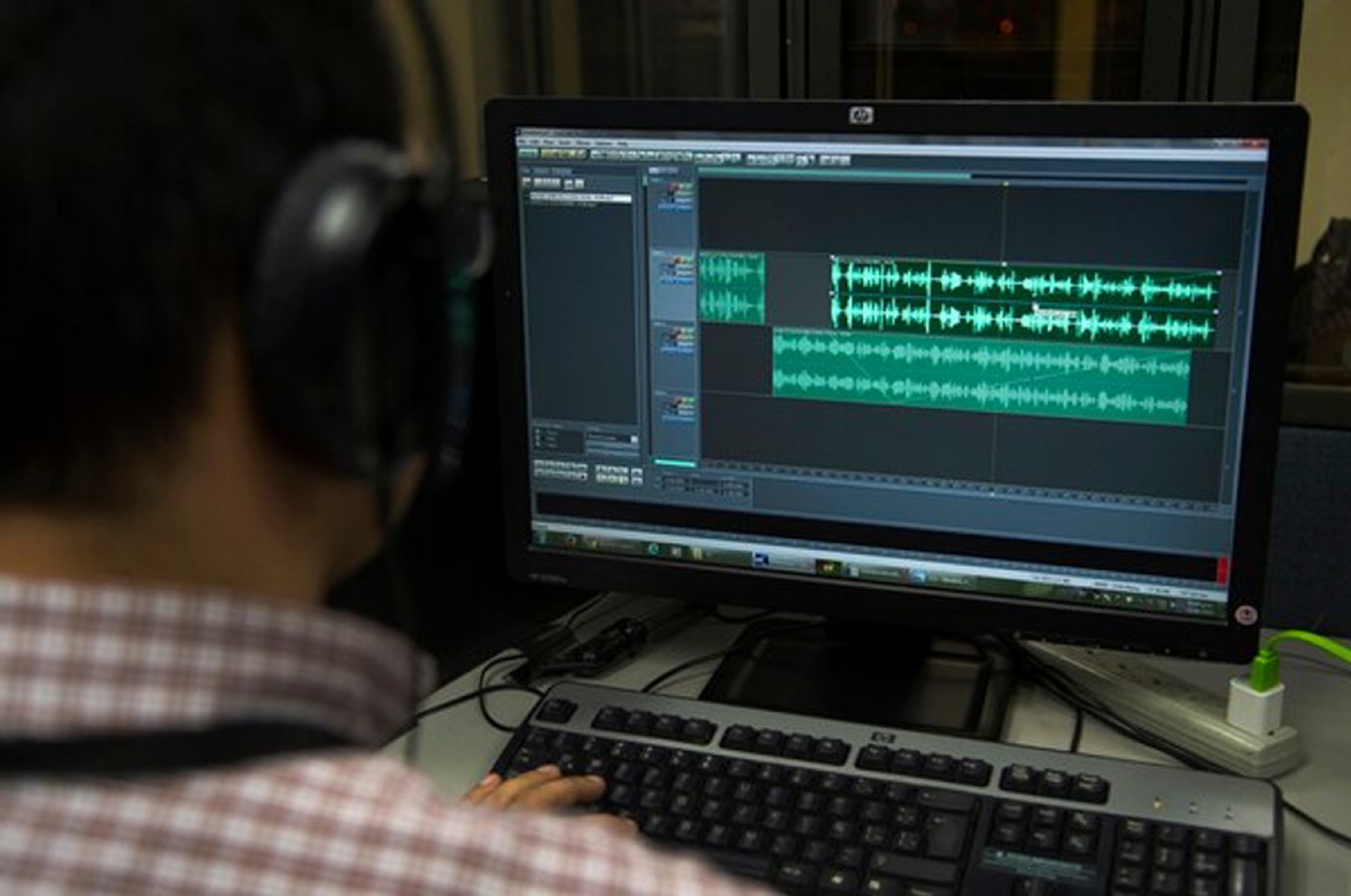
CIUDAD DE MÉXICO (apro).- Estudiantes e investigadores de la licenciatura de Ciencia Forense de la Universidad Nacional Autónoma de México (UNAM) trabajan en la construcción de una base de muestras que será útil para identificar voces en casos de secuestro y extorsión.
Fernanda López Escobedo, quien lidera el proyecto en la Facultad de Medicina, explicó que integrantes del Seminario de Lingüística Forense desarrollan actualmente el Corpus de Lengua Oral del Español (CLOE) para realizar investigación en comparación forense de voz.
Antes del inicio de la pandemia de covid-19, los universitarios grabaron las voces de 145 voluntarios de tres grupos de edad y tres niveles de estudios en una cabina aislada de ruido, para medir diferencias en variables como la riqueza léxica.
“No hemos podido continuar con la recopilación de voces, por las medidas sanitarias instituidas por la pandemia, porque se requiere utilizar la cabina, que es un espacio cerrado, pero tampoco podríamos dejar que el hablante utilice cubrebocas, pues es un factor de variabilidad en la voz”, lamentó.
Actualmente su equipo segmenta las voces por fonemas, en especial los sonidos vocálicos, que son los más útiles para extraer características acústicas y aplicarlas en la comparación forense de voz.
“En realidad nuestro objetivo es con un fin forense, sin embargo, es de interés para otras especialidades”, dijo, refiriéndose a temas del procesamiento de lenguaje natural, al reconocimiento y síntesis de voz, entre otros ámbitos.
Para realizar el corpus, su equipo se apoya en investigaciones lingüísticas sobre los diferentes acentos y modismos del español de México para aplicarlo al ámbito de la lingüística forense, por lo que resaltó la importancia de mantener actualizadas estas investigaciones.
López Escobedo apuntó que en México hacen falta bases de datos en las ciencias forenses, ya que muchas áreas como la de análisis de voz comparan características o un patrón de una muestra que no se sabe a quién pertenece, contra una cuyo autor es conocido y “necesariamente lo tienen que hacer a partir del conocimiento de la frecuencia de esa característica en una población”.
De ahí la necesidad de bases de datos de lengua oral, así como de dactiloscopia, genética y odontología, que comparan características y obtienen la frecuencia de éstas en la población.
La investigadora comentó que el grupo continuará con el corpus una vez que las condiciones de la emergencia sanitaria lo permitan, y recordó que el Seminario de Lingüística Forense labora junto con el área de odontología forense para conformar un corpus sobre el habla de adultos mayores.
De acuerdo con la universitaria, las características acústicas de quienes utilizan prótesis se modifican en ciertos sonidos que involucran el sitio de la boca donde tiene la prótesis, por lo que su objetivo es determinar qué variaciones sufren los sonidos y caracterizar a un individuo por el uso o no de esos dispositivos.
Los investigadores trabajan en este proyecto con la División de Estudios de Posgrado e Investigación de la Facultad de Odontología UNAM, ya que ahí acuden pacientes que requieren o usan estos aditamentos y han decidido participar en el corpus.


